The problematics behind data modeling
Basics of data modeling
Suppose a large delivery company that deals with customers and their orders. Internally, the company needs to track its workers, warehouses, and cars to deliver the goods. Although this is a simplified scenario, we can already create a simple diagram describing the relations between the entities described above, so-called domain ontology.
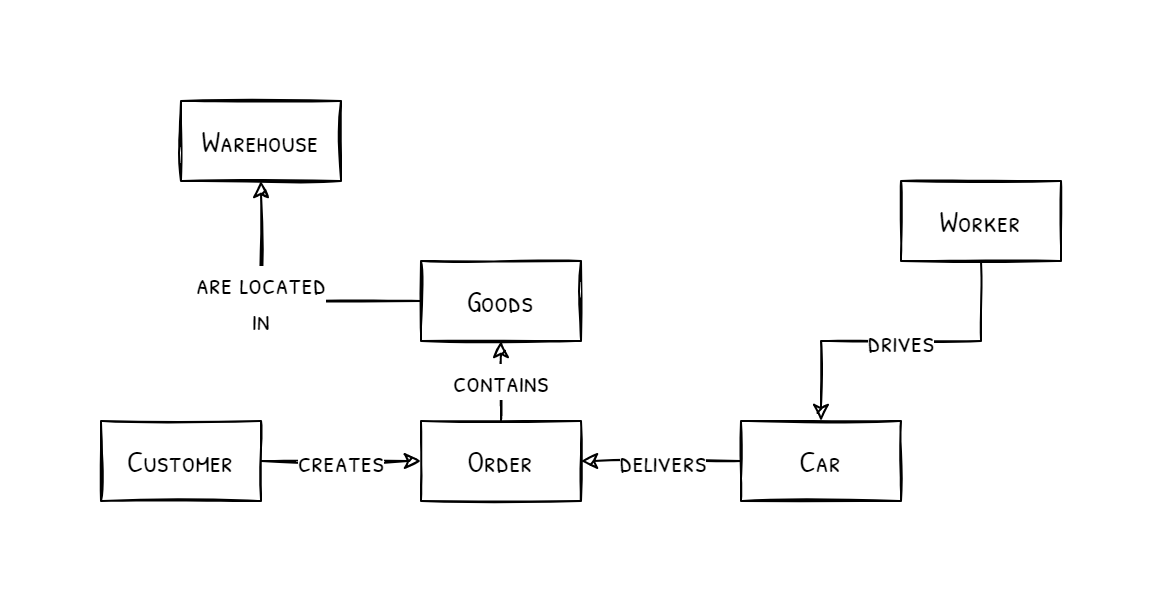
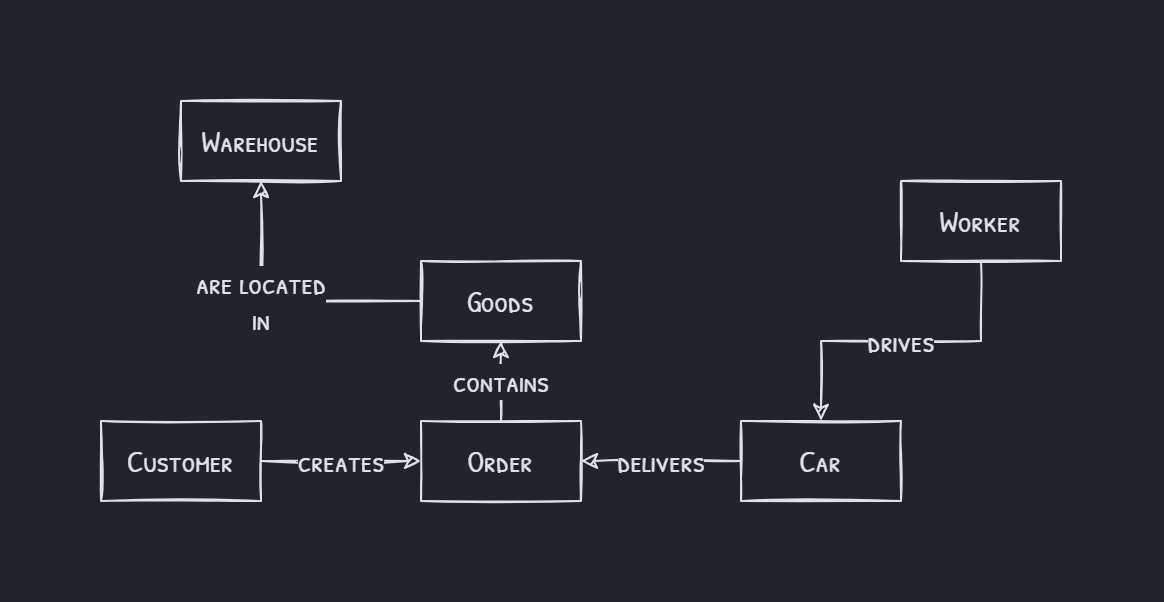
Software developers use this description with additional information to create a database and internal systems to operate the company, create orders and distribute the goods among different delivery cars.
Usually, multiple smaller systems are created, such as a website for customers, a system for warehouse operators, a mobile app for delivery workers, etc. To interchange the information between those apps, websites, and other company systems, both parties must agree on a common format and the technology. Most used technologies to interchange data are XML, JSON, RDF, or CSV. Format, or schema more technically, specifies how the data should be structured. It describes labels, data types, order of entities, etc.
Below are examples of different serialization technologies and different schemas used.
Sample data about a customer in JSON format
{
"name": "John",
"surname": "Doe",
"age": 35
}
Sample data about a customer in CSV format
name,surname,age
John,Doe,35
Sample data about a customer in XML format under different schemas
<person>
<name>John</name>
<surname>Doe</surname>
<age>35</age>
</person>
<Human>
<FullName>John Doe</FullName>
<age>35</age>
</Human>
Designing and managing schemas can be cumbersome as the technology changes over time, and newly created systems might have different requirements. Moreover, the company may use existing solutions instead of making every software tailored to its ecosystem. This may create other requirements on data that the systems will interchange. Additionally, the company may want to expose its data to customers through APIs, machine-readable formats, both for reading and writing. The image below depicts possible data exchanges between the systems and external users.
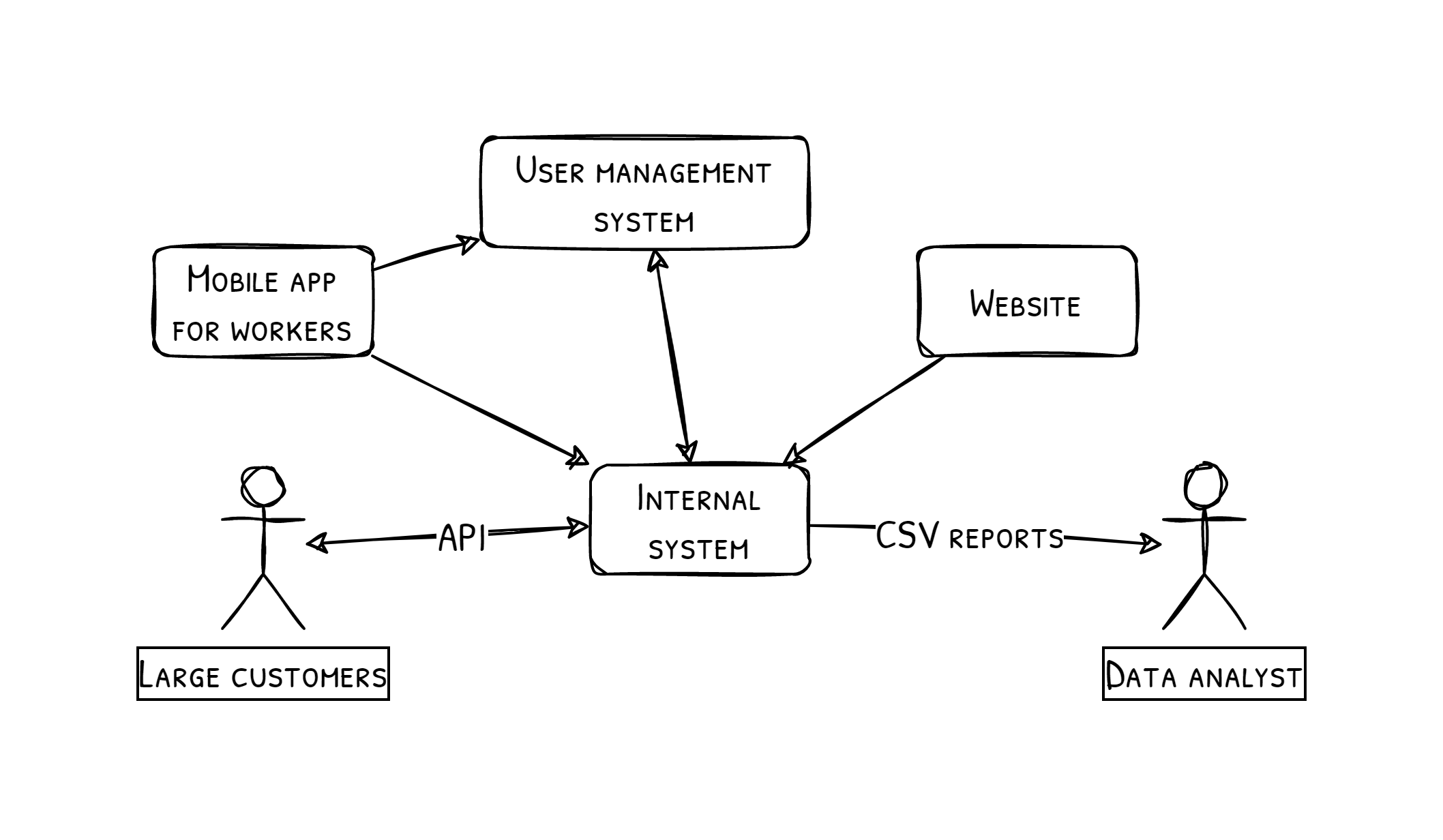
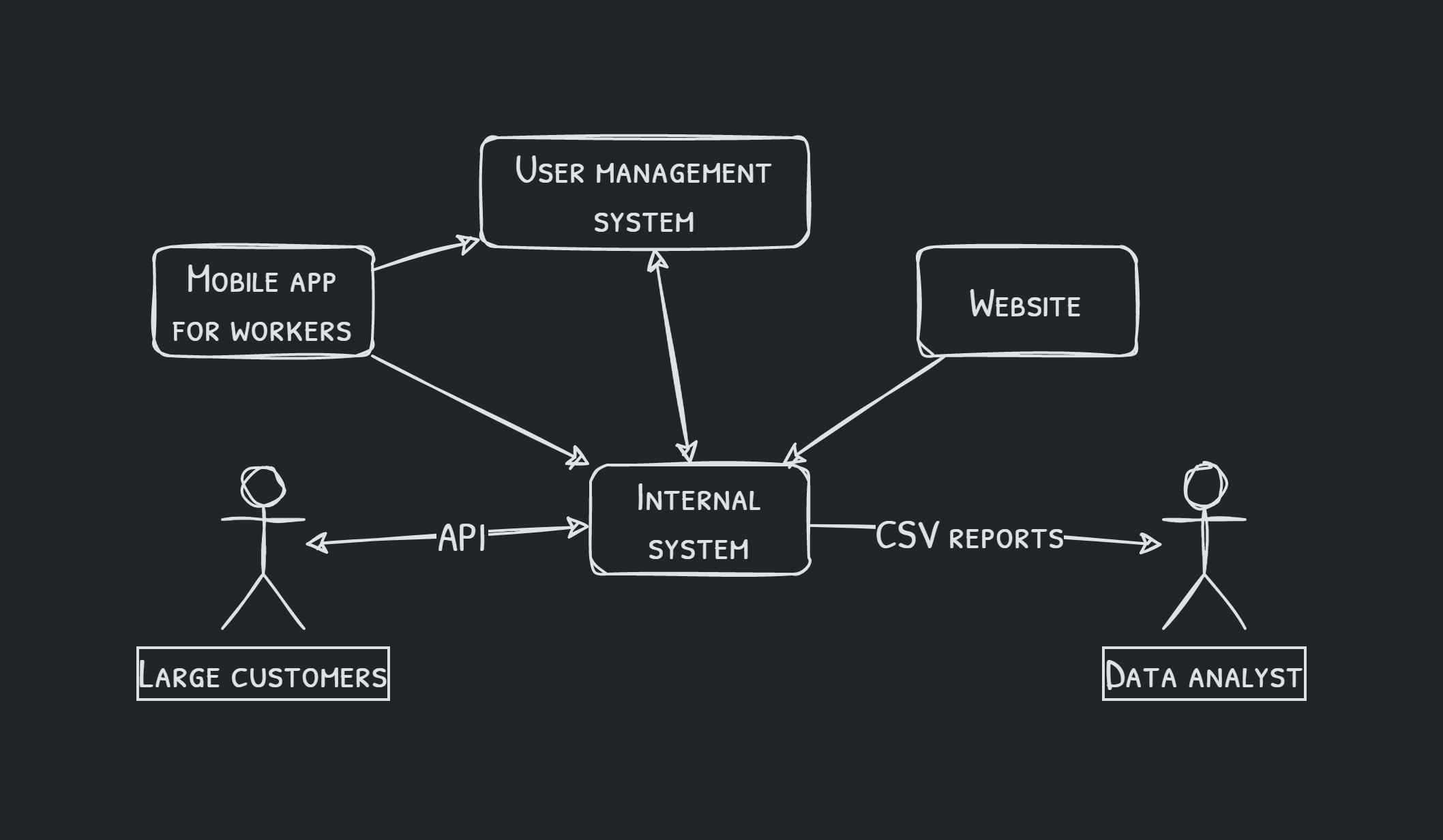
The challenge should be clear: There are many data interchanges in different formats that need to be documented, consistent with the domain schema, and possibly updated if new requirements arise.
Dataspecer
The goal of Dataspecer is to ease the task of creating, managing, and updating data specifications, making it easy for non-programmers to maintain the whole process. Further, it can generate technical documentation which describes the given schemas for programmers that will use the generated schemas. It can also create data transformations that may be handy if it is required to convert data from one schema to another, for example, between JSON and XML.