Expanding the Dataspecer Tool for API Creation and Management
Introduction
The project “Expanding the Dataspecer Tool for API Creation and Management” was developed within the scope of class Research Project (NPRG070) at Charles University in Prague. This report serves the purpose of providing a comprehensive overview and analysis of the project. To be more precise, the report begins with the motivation for the project. Next the report provides user stories to comprehend the essence of the end-user requirements. Conversely, it proceeds by describing and showcasing how the program works. Lastly, the report takes a closer look in the code and provides information regarding the system design and key technical decisions.
Motivation
Dataspecer represents a tool which is being developed at the faculty of Mathematics and Physics of Charles University. It serves the purpose of managing as well as modeling data structures. Conversely, it automates different types of tasks with respect to data schemas. Despite the fact that the capabilities of Dataspecer are extremely advanced, there are directions in which the tool could be expanded. My motivation of pursuing this project was exactly the fact that the tool did not support the process of API creation and management – more precisely generation of API specification and its maintenance. Nowadays, APIs represent a pivotal part of the tech industry. According to CISCO, Internet of Everything (IoE) represents a networked connection of four units. These units are: people, process, data and things [1]. APIs on the other hand represent the point of connection between products and services which means that they allow aforementioned four units to communicate with one another [1]. Given their crucial role in enabling seamless interaction as well as integration across various platforms, the relevance of the APIs cannot be overstated. Conversely, when we talk about API creation and management in the context of this project, we specifically refer to the generation of API specifications (in OpenAPI format) and their maintenance. By developing the feature of creating API specifications and maintaining them, the expanded version of Dataspecer can significantly streamline the development process, ensuring that APIs remain up-to-date and are fully functional as data structures and requirements evolve. This expansion not only enhances the tool's utility but also aligns it with the current demands of the tech industry, where efficient API management is essential for the development of various systems.
1 Exploring User Perspectives through User stories
In any research project it is paramount to understand the needs and aspirations of the end-users. The aim of this chapter is to capture the essence of the user requirements by providing following user stories:
I as an API designer who already works with the Dataspecer tool want to generate API specification based on the artifacts (data structures) designed in Dataspecer, so that I am able to utilize the same tool not only for data modeling but also for creating respective API specifications.
I as an API designer want to generate API specifications in OpenAPI format so that my APIs are compliant with the industry formats.
I as an API designer want to customize certain fields of my API specifications so that I can meet specific client requirements.
I as an API designer want to go back to my latest saved configuration so that I can ensure consistency in the API design process.
I as an API designer want to receive suggestions about paths (endpoints) so that my design process is simpler.
I as an API designer want to design operations not only for the data structures on the main level, but also for the data structures that are one level below, so that I can ensure granular control and organization of API endpoints.
I as an API designer want to choose if I am manipulating a collection or creating an operation just for a single resource so that I can design APIs that cater to variety of use cases.
I as an API designer want to be restricted in submitting the same operation name to multiple different operations, so that I can maintain clarity and avoid ambiguity in the API specification, ensuring that the developers are able to interpret the generated API endpoints accurately.
I as an API designer want to be restricted in submitting two same operation types to one path (endpoint), so that I can enforce consistency and adherence to API design practices.
I as an API designer want to download JSON representation of generated API specification from my designer tool, so that I can share it with stakeholders and team members easily.
I as an API designer want to copy the generated API specification with a button from my designer tool, so that I can transfer it to different documents or emails in a timely manner.
I as an API designer want to open Swagger Editor with a button in my designer tool so that I can utilize its graphical interface.
2 Key Conceptual Decisions
At first Dataspecer was analyzed. Handling data specifications consisting of different data structures represents a standout feature of the tool. More precisely, the tool has access to various conceptual models and the user is able to design specific data structures based on those conceptual models within the data specification. Because of this standout feature, it was decided to utilize a resource-oriented approach whilst developing the project. Based on the analysis, Dataspecer is highly compatible with the concepts of RESTful APIs. To be more precise, when it comes to REST APIs, fundamental concept is resource [2]. More precisely, a resource represents an object that has a type, associated data, relationships to other resources as well as a collection of operations performing different manipulations on it [2]. On one hand data structures designed via Dataspecer have a type, attributes and associations however the information regarding the set of methods operating on them is not available in the tool. Therefore, when it came to mapping the concept of resources from RESTful APIs to the data structures designed via Dataspecer it was crucial to obtain information about the aforementioned operations. In the context of this project, this means that in order to be able to generate API specifications corresponding to the data specifications, the information regarding the methods operating on data structures (within the data specification) need to be obtained. Because of this, desired information is specified by the user in the new extension and is utilized for project purposes – API creation and management, more precisely generation of API specifications and their maintenance.
Data Structures designed in Dataspecer may have multiple levels. However, in the context of API generation it is logical to create operations for main data structure and data structures which are one level below it. Going beyond this level of nesting would make the form overly complex and difficult for users to comprehend the core functionality of the operations. Moreover, operations beyond the second level are considered often redundant since they tend to be too granular. This means that they would acomplicate the interface without providing significant additional value. Because of this, one of the key conceptual designs made within the scope of this project was to limit the operations to the first two levels which ensures clarity as well as usability of the program.
As mentioned above, a resource-oriented approach was employed for project development. OpenAPI standard was chosen as the format of developed API specifications since OpenAPI standard (OAS) defines a standard representing a language-agnostic interface to RESTful APIs [3]. OAS enables both humans as well as machines to explore and understand the functionalities of the service even in the absence of source code, documentation, or the need for network traffic examination [3].
In order to provide further clarification regarding key conceptual decisions, it is essential to consider why AsyncAPI was not chosen as a format for generating API specifications. As said, Dataspecer and its capabilities were analyzed thoroughly. The analysis made it evident that data structures designed via Dataspecer are highly compatible with the principles of REST, which in turn seamlessly aligns with the OpenAPI standard. Initially, it might have seemed that OpenAPI and AsyncAPI would be similar. However, they not only serve different purposes but also support distinct communication protocols.
The main focus of AsyncAPI is Event-Driven Architecture (EDA). In event-driven architecture the main emphasis is on events. In EDA events are utilized for triggering and communicating between different services that are decoupled [4]. In this context, event is a state change or even an update – for instance, an item being added to a shopping cart on an e-commerce website. To be more precise, events either contain state or act as identifiers [4].
Current version of Dataspecer does not provide information regarding events, which would be prerequisite for creating specifications in AsyncAPI format. Conversely, the effort needed to develop such specifications would be disproportionately high compared to the benefits given the current capabilities of the tool. Based on this information, the decision of adopting the OpenAPI standard was made which better aligns with the resource-oriented approach and data structures which are supported by Dataspecer.
3 Functionalities and Operation
Now that motivation for the project as well as key conceptual decisions are already considered the functionality as well as operation of the developed program may be discussed. As mentioned, the program generates API specification in OAS based on data specification created via Dataspecer. Because of this, the quality of the generated OpenAPI specification highly depends on the quality of the data specification which is taken as input by the program. Please note that the program assumes unique names of the data structures. This section will demonstrate the working process of the extension based on an example data specification called “Sample Data Specification”. This data specification consists of two data structures. These data structures are: Tourist Destination and Member. Please refer to Pic 3.1 and Pic 3.2 in order to view the representation of aforementioned data structures.

Pic 3.1 – Representation of Data Structure “Tourist Destination”

Pic 3.2 – Representation of Data Structure “Member”
3.1 Accessing the extension – API creation and management
Now that the input data structures are already presented, the actual
extension may be discussed.
Before moving on to the actual program, it has to be noted that the
Dataspecer tool is equipped with a manager (currently in development)
which may be accessed via following url:
https://tool.dataspecer.com/manager/ . In order to generate OAS the
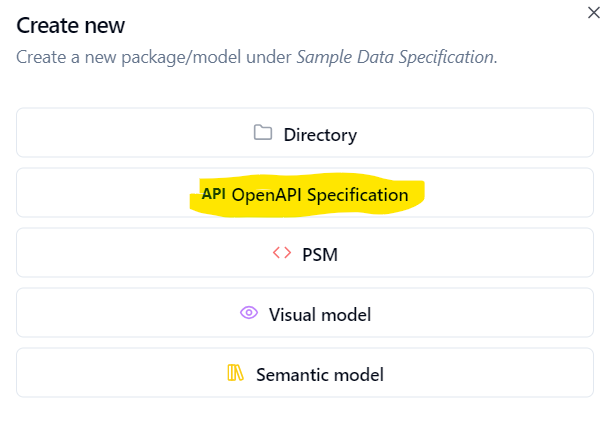
user has to access the Dataspecer manager and find desired data
specification. Once the data specification is found a plus button on the
right side needs to be clicked and the manager will display various
options. OpenAPI Specification represents one of the proposed options.
Once the user clicks on OpenAPI specification option, he/she will be
asked to create a name and description for the package. Please refer to
Pic 3.1.1 and 3.1.2 below in order to view the steps needed for creating
OAS package.

Pic 3.1.1 – Step 1: View of Dataspecer Manager and plus button
Pic 3.1.2 – Step 2: View of Dataspecer Manager once plus button is clicked
Once this button is clicked the user needs to provide name and description for the option and then click “Save Changes”. Once this process is complete, the user will be able to view the newly created package/model in the Dataspecer manager under the desired data specification. Each OpenAPI Specification package/model has an edit button on the right side. Once the user clicks this button, he/she is redirected to the extension. Please refer to Pic 3.1.3 in order to view the newly created OpenAPI specification package/model.
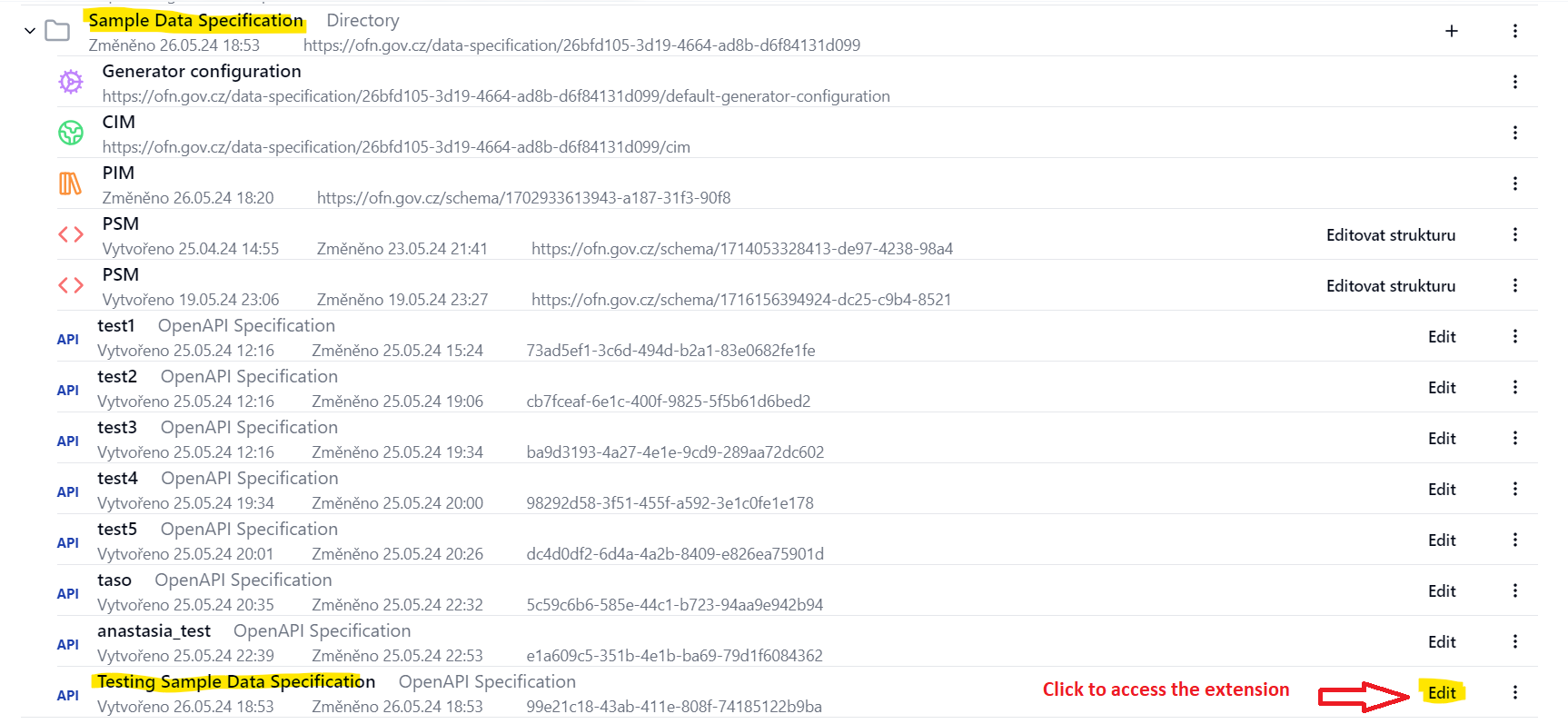
Pic 3.1.3 – Step 3: newly created OpenAPI specification package/model
3.2 Creation and Management of APIs – Working Mechanisms
Now that the navigation to the extension as well as its initial input is already considered, the actual program may be discussed. Once the user navigates to the extension, initially he/she is presented with an empty form. The user has to fill in following information: API title, description, version and base URL. Next section of the form is dedicated to the data structures and operations/methods operating on them. In order to fill in the information about the data structures the user has to click “Add Data Structure” button. Please refer to Pic 3.2.1 in order to view the screenshot of the resulting display once the initial data – title, description, version and base url are provided as well as data structure is chosen.
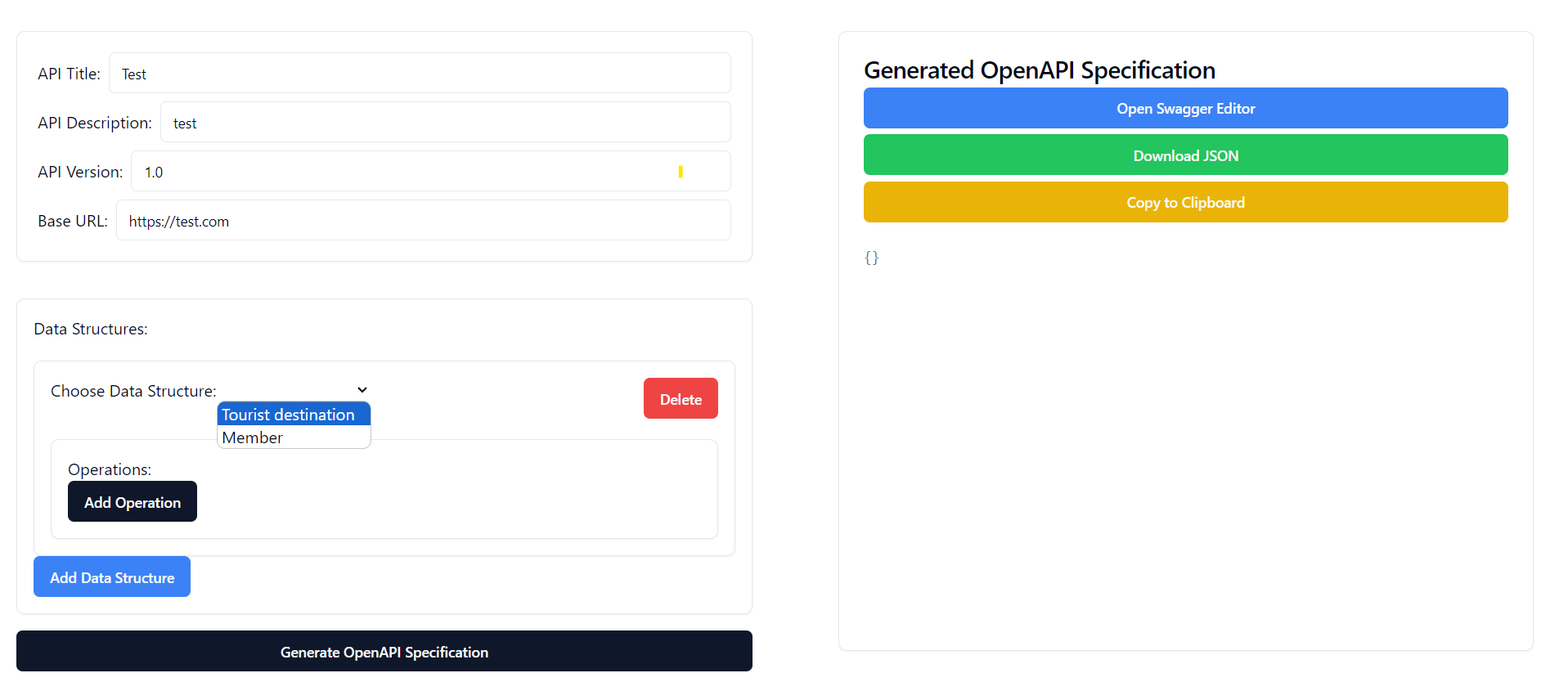
Pic 3.2.1
After this step the user is able to add operations for the chosen data structure by clicking add operations button. Once this button is clicked a new section appears where the user has to provide information about the operation. The section has two switches. The first switch labeled “Association Mode” decides if the operation is for the main data structure (chosen at the beginning) or one level below it. A concrete example will be shown later in this section. The second switch labeled “Manipulate a collection” decides if the operation performs a collection of resources or a single resource manipulation. Furthermore, the user has to provide name for the operation and its type (for instance: POST, GET, DELETE etc.). Based on this information the program generates suggested path which can be copied into the endpoint field as input. The user is also able to add a comment to the operation and add a response code to it. To sum up, following operation information is needed:
- Whether the operation refers to the main data structure or to a data structure which is one level below the main one.
- Whether the operation performs a collection of resources or a single resource manipulation
- Operation name
- Operation type
- Endpoint (path for the operation – in the best-case suggested path generated by the program)
- Comment about the operation
- Response code for the operation
Once this information is filled in, the user is able to either add another operation and continue in the same manner or click “Generate OpenAPI Specification” and view the output on the right side of the page. Please note that once this button is clicked the configuration (filled in information) is saved on the Dataspecer backend and the user is able to go back to the current progress and continue from that point.
Let’s consider an example of generating API specification for Tourist destinations. According to the data specification, provided in the beginning of this chapter, Tourist destination has following associations and attributes:
- Capacity of type integer
- Owner of type human or person
- Contact of type contact
If these properties are not of primitive types (are attributes), they may be considered as data structures as well. In this case, Owner and Contact are considered as data structures however, the schema of owner is not defined whereas contact has following attributes and associations:
- Email of type string
- URL of type string
- Phone number of type decimal number
- Has contact of type workplace which in turn has a page of type page
Following example will provide three kinds of operations in order to showcase the functionality of the program. These operations are:
- CreateTouristDests – operation that creates an object of type tourist destination and adds to the collection (of tourist destinations)
- GetTouristDests – operation that retrieves a collection of tourist destinations
- CreateContact – operation referring to a data structure one level below the main data structure (Tourist destinations). This operation creates objects of type contact.
Please refer to Pic 3.2.2, 3.2.3 and 3.2.4 on the next page in order to view the resulting display of corresponding form.
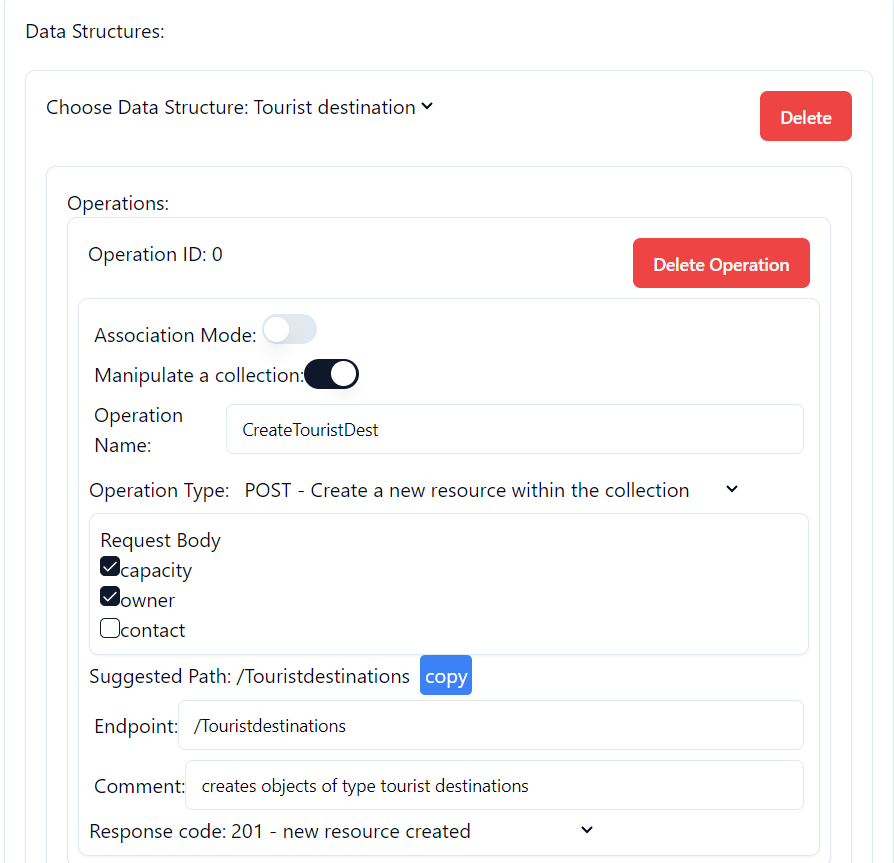
Pic 3.2.2 – Operation creating Tourist Destinations
As one can see, Pic 3.2.2 represents the operation for creating tourist destinations. Since tourist destination is the main data structure and this operation is intended for it, the association switch is off. However, since the operation represents collection manipulation – in particular adding a resource (in this case tourist destination) to a collection (collection of tourist destinations) the collection switch (“Manipulate a collection”) is on. Next the operation name is provided and operation type is chosen. Please note that, if manipulate a collection is marked on, the user gets two options in the operation type select. These options are GET and POST. In this context, GET means retrieving collection of resources while post represents create a resource and adding it to a collection. If the user has collection switch off, different options focused on manipulating a single resource, such as deleting a specific resource, retrieving a specific resource etc. are provided. As one can see, in case of post request the user is also able to choose which fields have to be passed in the request body. Next the program generates suggested path and allows the user to copy it. The path has to be provided in the endpoint field. Furthermore, a comment can be added to the operation for the purpose of increasing clarity. Lastly the user chooses respective HTTP response code.
The information for the next two examples were filled in similarly. However, there are minor differences. The next example showcases retrieving a collection of resources. Please note that in case of GET operation, no request body is provided. Please refer to Pic 3.2.3 in order to view the screenshot of the resulting display.
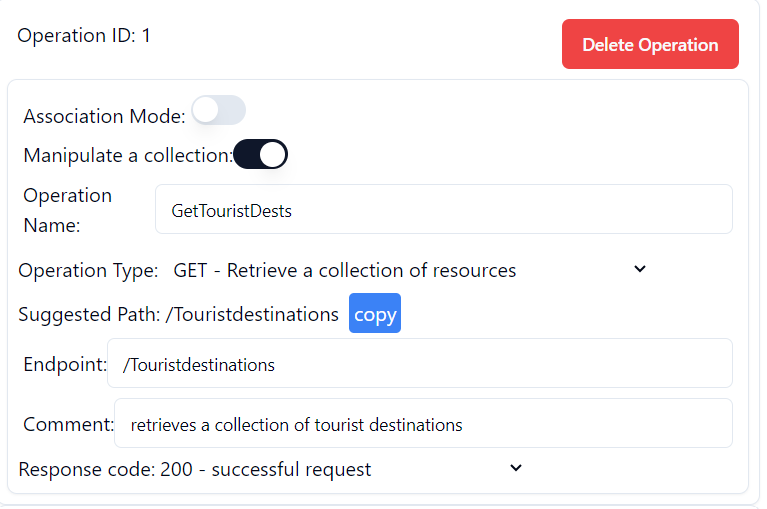
Pic 3.2.3 – Operation retrieving collection of Tourist Destinations
The last example demonstrates how to create operations for one level below the main data structure. In this case contact is chosen as target data structure. In order to be able to choose contact the association switch (“Association Mode”) has to be on. Moreover, please refer to the updated suggested path based on the new target data structure. Please refer to Pic 3.2.4 in order to view the screenshot of the resulting display.
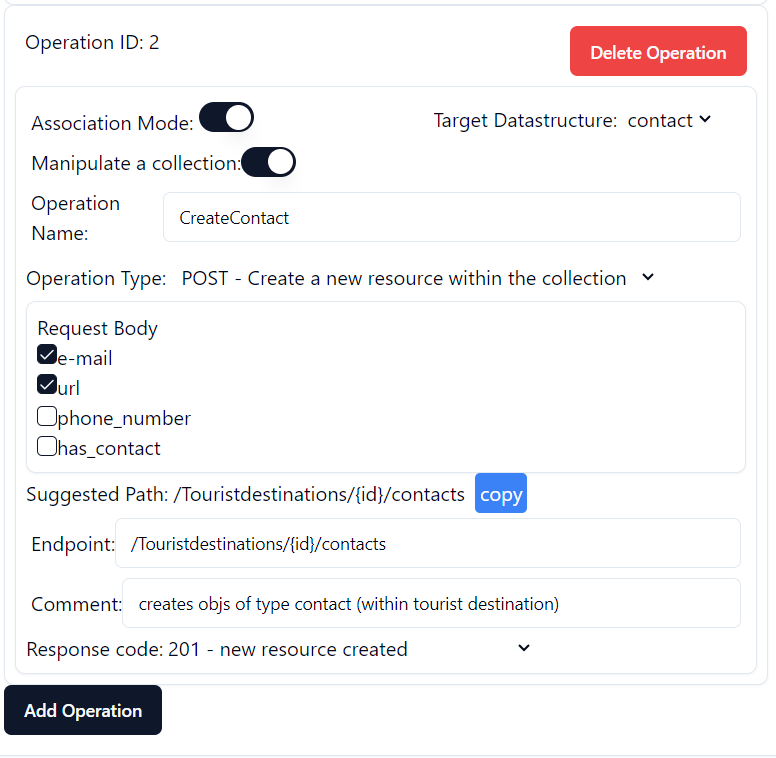
Pic 3.2.4 – Operation for creating contact (target data structure is one level below main ds)
Now that the left side of the form is already considered, the right side may be discussed. The right side of the page is dedicated for showcasing the output – generated OpenAPI specification. There are three buttons available to the user. These buttons are:
- Open Swagger Editor – opens Swagger Editor
- Download JSON – downloads generated OpenAPI specification in json format
- Copy to Clipboard – simply copies generated OpenAPI specification
Once the user generates OpenAPI specification it would be beneficial to copy the output by clicking the “Copy to Clipboard” button and paste it in the Swagger Editor. In this case the user is able to have a better understanding of the generated OAS since Swagger Editor also provides graphical representation of the output.
3.3 OpenAPI specification as output of the project
Now that the input of the program is already considered, output may be discussed. As said, once the user clicks “Generate OpenAPI Specification” button corresponding OAS is presented to the user. Generated OAS consists of following sections/constructs:
- openapi – specifies the version of OpenAPI (3.0.0)
- info – specifies information regarding OAS, in particular: API title, description and version
- servers – specifies base URL for the API
- paths – specifies paths and their respective operations (provided by the user)
- components – represent containers for various reusable definitions. In the context of this projects data structure schemas are stored in the components section.
- security – represents the authentication methods utilized in the API (set to basic auth).
Now that the structure of the output is already considered, let’s have a look at the generated OAS based on the example considered earlier (in 3.2).
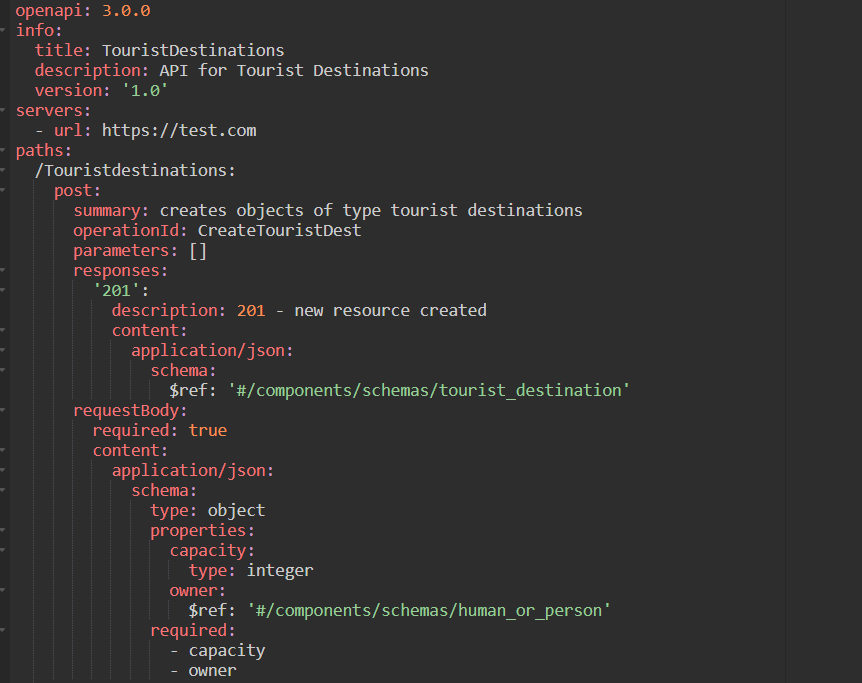
Pic 3.3.1- Output OAS: openapi, info and path with POST operation
Pic 3.3.1 demonstrates how the user input is reflected in the output. As one can see, form inputs – API title, description as well as version are utilized to populate the info section of generated OAS whereas base URL provided by the user is utilized in the server’s section. As for the paths and operations, form input data related to the operations is used for populating paths and their respective operations.
Conversely Pic 3.3.2 represents s a more interesting example. It exemplifies how GET collection operation is represented in the OAS output. Please note that aside from the trivial output, as seen in the first example, the program is also able to generate query parameters where necessary. This means that when it comes to collection retrieval, the user is able to query the result based on the fields of chosen data structure. Because in this case the goal is retrieving a collection (not a single resource), the program specifies in the responses that an array has to be returned. Please refer to 3.3.2 below in order to view the screenshot of the resulting display.
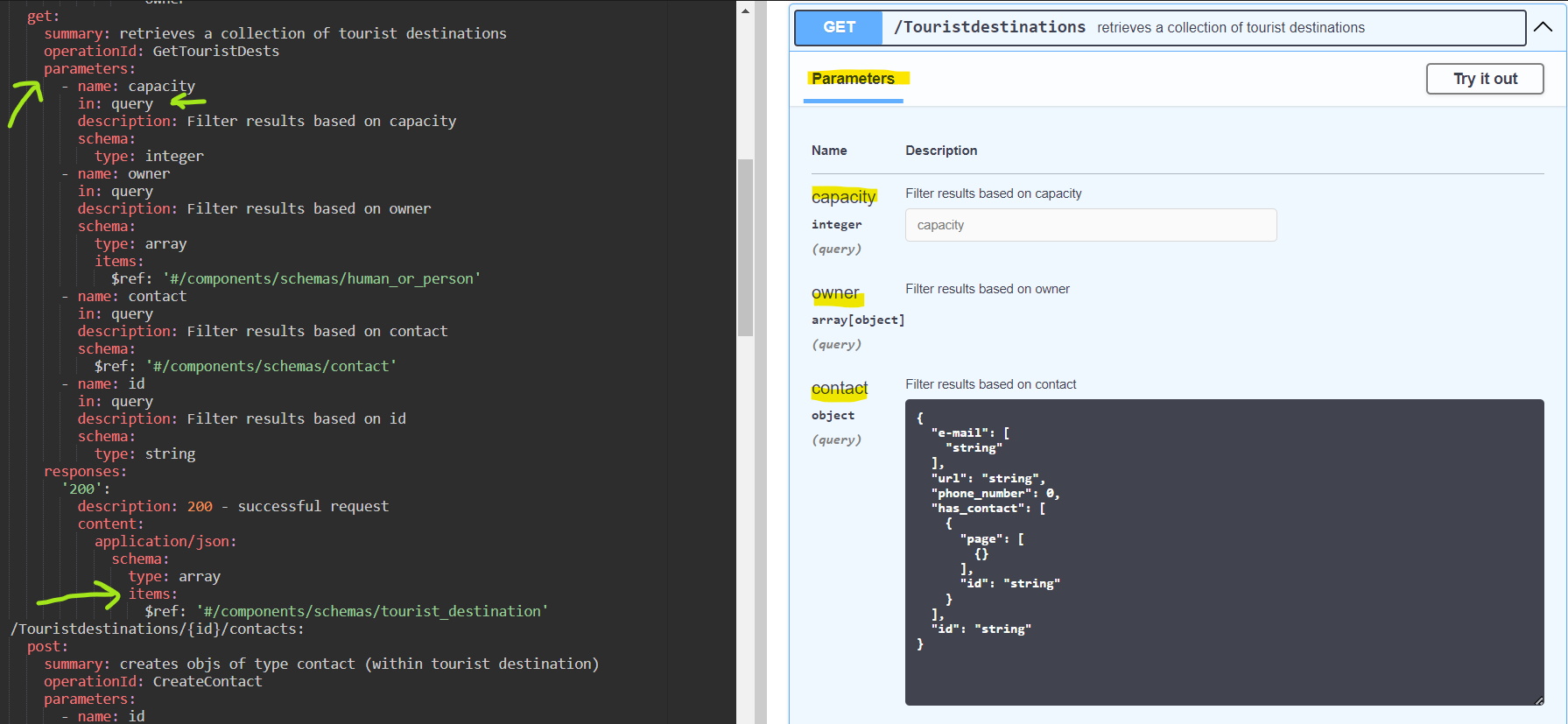
Pic 3.3.2 – Output OAS: path with GET operation
Third operation is related to contact data structure (which is one level below the main data structure). It behaves in the same manner as the first example. The program is able to detect the nesting and instead of referencing main data structure schema, it references schema of contact.
With all other sections thoroughly examined, the final topic to address is the components section. Components section does not require any direct user input from the Dataspecer extension. It relies on the data specification and respective data structures. The program provides a schema in OAS format considering if attribute/association is mandatory or optional as well as whether it represents an array (collection) or a singleton object. If data structure was not designed before OAS generation, the program also appends a description, notifying the user that this data structure needs to be filled in. Please refer to Pic 3.3.3 below in order to view the screenshot of resulting display of Touristdestination schema as well as respective schemas of its associations.
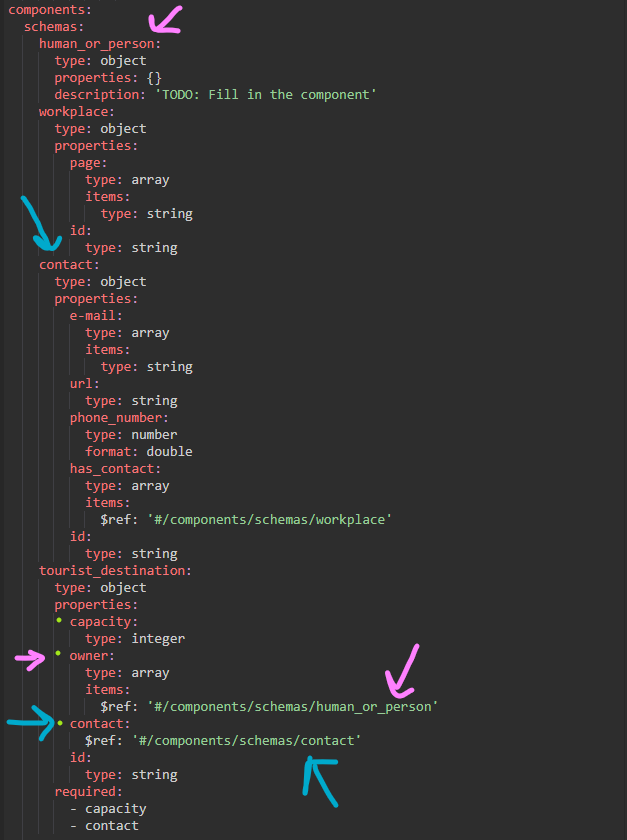
Pic 3.3.3 – Tourist Destination schema and respective schemas for its associations
According to Pic 3.3.3 one can see clearly that object of type tourist destination has three properties to of which are not of primitive data types – owner and contact. Owner represents an array of objects of type human_or_person whereas contact represents an object of type contact. Since no properties were defined for human_or_person its description says that the component needs to be filled in. On the other hand, according to the schema of contact, an object of type contacts has emails (a collection of strings), url (string), phone numbers (collection of numbers) as well as has_contact which also represents a collection of objects with type workplace. The schema of workplace is also present in the components section and follows the same manner.
4 Technical Overview
4.1 Organization
Having discussed functional and operational aspects, an essential part of providing a comprehensive overview of the project is to consider its technical structure. The project, located within the ../applications/api-specification directory, exhibits an organized arrangement within its source code, predominantly housed within the src folder. The codebase is systematically partitioned into distinct directories – each serving a particular purpose and fostering clarity and maintainability.
As said, src directory encapsulates primary codebase including several pivotal directories. These directories are:
- components - This directory serves as a repository for imported components sourced from shadcn-ui. These components were selected because of their quality and functionality. They contribute to the cohesive user interface design.
- customComponents – This directory serves as a repository for bespoke (custom) components. The goal of these components is to address the distinct demands of the project. By utilizing both – pre-imported components from the components directory and handcrafted HTML elements, these components are equipped with specialized features essential for seamless form operations.
- Models – The Models directory retains TypeScript interfaces and types utilized extensively across the source code.
- Props – Here reside TypeScript type definitions that outline the properties passed to custom components.
Furthermore, there are several notable files located at the root of src directory. These files are: DataStructureFetcher.tsx, DataTypeConverter.tsx, FormValidationSchema.tsx, OApiGenerator.tsx and MainForm.tsx. The interesting points of each of these files are discussed later in this chapter – in 4.4 Key Technical Decisions.
4.2 Important Dependencies
This section is dedicated to inform the reader regarding important dependencies of the project. The most important package installed in the project is react hook forms. This library streamlines form development by simplifying form management and validation process. Another important package installed in the project is react hook form validation resolver (@hookform/resolvers). In particular validation with zod was used in order to validate form before generating the OAS. As for the UI, the components were imported from shadcn ui. Shadcn UI builds its components on top of the radix UI. The next important package utilized in the project is pluralize. Pluralize library was mainly used for the purpose of generating suggested paths. However, please note that valid plural names (words) are produced only in case of English names. The last important package is swr which is a library for data fetching. This library is used for downloading the data from Dataspecer backend. Please refer to the list of important dependencies and their versions below:
- @hookform/resolvers: ^3.3.4
- @radix-ui/react-checkbox: ^1.0.4
- @radix-ui/react-dropdown-menu: ^2.0.6
- @radix-ui/react-label: ^2.0.2
- @radix-ui/react-select: ^2.0.0
- @radix-ui/react-slot: ^1.0.2
- @radix-ui/react-switch: ^1.0.3
- pluralize: ^8.0.0
- radix-ui: ^1.0.1
- react: ^18.2.0
- react-dom: ^18.2.0
- react-hook-form: ^7.51.3
- styled-components: ^6.1.8
- swr: ^2.2.5
- uuid: ^9.0.1
- zod: ^3.23.4
4.3 Build Instructions
In order to build the project, one needs to follow these steps:
- At first, clone the whole mono repository via git clone …
- Please set up a local environment by creating following file: .env.local. A local environment variable called VITE_BACKEND needs to be defined within this file. The variable needs to be set to the backend URL (e.g. https://backend.dataspecer.com).
- To install all packages, please run npm install from the root of the repository.
- For building the dependencies of this application npm run build needs to be run.
Please note that it is possible to run live server with the command npm run dev from this directory. However, before running the live server, all of the necessary dependencies need to be already built.
4.4 Key Technical Decisions
Having discussed organization as well as important dependencies, it is time to consider key technical decisions. As mentioned earlier, there are several files located in the src directory that represent the key files on which the project is based. Before moving on to them, the model of the data structure utilized across the codebase has to be presented. Please refer to Pic 4.4.1 in order to view the screenshot of the corresponding representation.
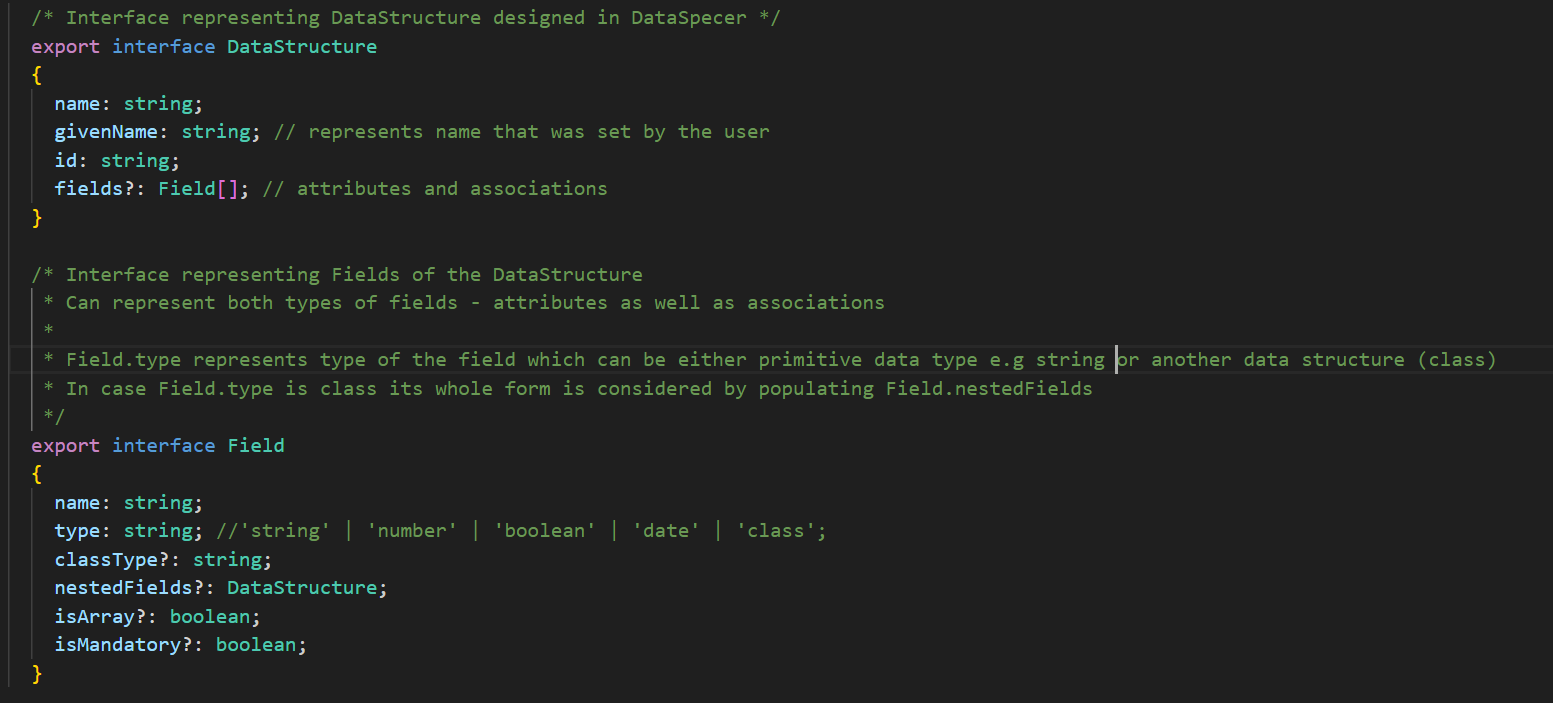
Pic 4.4.1 – Representation of Model Data Structure
Now that the general structure of data structure is already showcased, a particular example of Tourist destination may be considered. Please refer to Pic 4.4.2 in order to view particular example of Tourist destination.
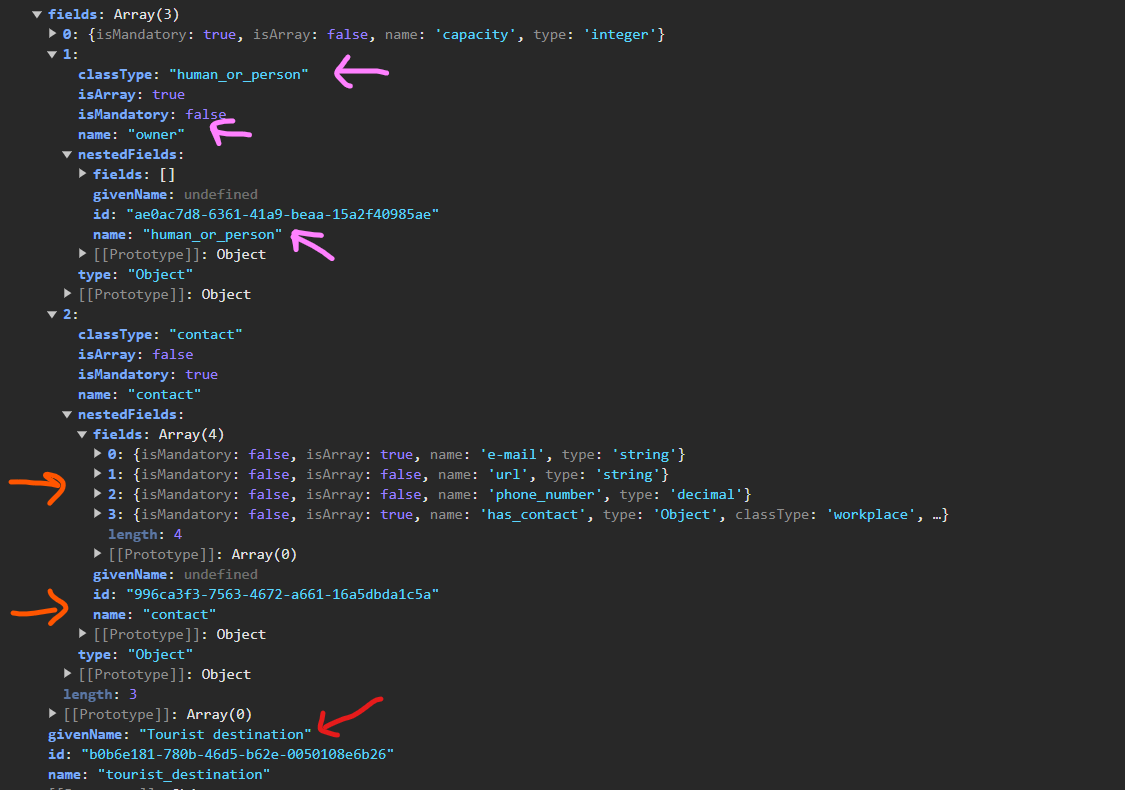
Pic 4.4.2 – Tourist Destination as Data Structure
As seen on the example, Tourist destination represents the main data structure and its attributes and associations are represented by the fields. In case the field is of primitive type (is an attribute), its type is specifically written in Field.type. Field “capacity” exemplifies this approach, since it has type integer and represents an attribute. In this case type is specified in the type field directly. However, in the case of having an association thus not of primitive type, Field.type contains “Object” and Field.classtype is populated with corresponding type. Conversely, the entire representation of this multi-level data structure is considered by populating Field.nestedFields. Please refer to the orange arrows on the screenshot. According to this example, contact represents an association and is a field of type not primitive data type. Because of this, contact’s type is specified as “Object” and it’s classType is specified as “contact” (as specified originally when creating this data structure in Dataspecer tool). Moreover, contact has several fields: email, url, phone number and has contact – all of which are located in the nestedFields property.
As the first point the program fetches data about data specification, in particular about its data structures from the Dataspecer backend and stores in a collection consisting of objects conforming to the structure described above. The logic performing this task is located in DataStructureFetcher.tsx. The URL of the current window contains the identifier of the target data specification. Based on this id the program fetches information regarding data structures which are contained by the target data specification. More precisely, the iris (identifiers) of contained data structures are fetched. Once the ids are obtained, particular data about each data structure is fetched. Having obtained whole data, the information is stored in an array which in turn is then processed to get the data structures in the format which was described above. Each data structure is divided into operations and resources (on the Dataspecer backend). The interest of the program is resources object. It contains following information: data structure name as well as information regarding attributes and associations. The information about associations is processed recursively because of the possible multiple levels of data structure. The output of this process is list of data structures in the aforementioned format.
Now that the fetching process is already considered, OAS generation may be discussed. The logic regarding the OpenAPI specification generation is located in OApiGenerator.tsx. Main method responsible for OAS generation is called generateOpenAPISpecification which in turn calls its helper functions. The method takes two parameters as inputs – datastructures and userInput. Parameter datastructures contains information which was fetched from Dataspecer backend about target data specification. This means that this parameter represents a collection of data structures from the target data specification in aforementioned format. As for the userInput, this parameter represents the information which was provided by the user via the user interface. More precisely, userInput parameter contains information regarding API title, description, base URL as well as operations defined for particular data structure. The consolidation of this information makes it possible to generate corresponding OpenAPI specification.
The generator iterates over the collection of fetched data structures and creates corresponding components schemas. The method responsible for creating component schemas (createComponentSchema) calls method dedicated for creation of properties (createProperties). CreateProperties method checks if the field is of primitive type or not. If not then it calls createComponentSchema on the field and therefore creates component schema for the nested data structures too. It is important to note that the program also formats the names of the data structures since OpenAPI format only accepts certain characters. Any character which is not accepted by the OpenAPI standard is turned into an underscore. What’s more the program takes the detected properties (fields) into consideration and if data structure does not have any, the program appends following description: “TODO: Fill in the component”. Furthermore, the program appends id field of type string to each component schema so that they each have unique identifier.
Now that the main principles of component schema generation are already considered, paths and their respective operations may be discussed. The generator iterates over the data structures from the user input. Usually, each data structure contains collection of operations – specified via the user interface. For each operation method called handlePathOperations is called. This method constructs operation objects for the particular path. Moreover, the method also considers the type of the operation and in case the operation type is GET, query parameters showcased in subchapter 3.3 are also generated. When it comes to constructing operation object, dedicated method for this is – createOperationObject which in turn calls other helper functions to generate operation object in its full form by including corresponding request body as well as response.
It is also important to consider the file FormValidationSchema.tsx. In order for OpenAPI specification to be valid it is necessary that the combination of operationtype (e.g GET, POST, DELETE etc.) as well as the endpoint (path) is unique. For instance, each path may have only one GET operation object in it. Moreover, the OpenAPI standard requires that the name of the operation (in the OAS called operationId) is unique. Since all of this information is provided by the user, this data is validated in the UI. This means that the developed form does not allow user to submit invalid data. All of this is achieved via zod library dedicated to form validation. Please refer to Pic 4.4.3 and 4.4.4 in order to view the screenshots of the error messages displayed to the users in case of unsuccessful validation.

Pic 4.4.3 – Error message regarding the combination of operation type and path (endpoint)

Pic 4.4.4 – Error message informing the user that the operation name must be unique
The project includes converter for data types (DataTypeConverter.tsx). The converter adapts data structure type names from Czech language to English. The second converter adapts English data types to the data types which are accepted by the OpenAPI standard.
Last but not least, MainForm.tsx contains the logic of the user interface. Two types of data are fetched. First – the information about data structures inside target data specification and second – pre-saved values of the UI form. Moreover, a very important aspect of the MainForm component is that, upon submission of the form, not only the OpenAPI specification is generated, but also current configuration (user-provided information) is saved on the Dataspecer backend. This means that the form is able to retain values and the user is able to continue designing their API from the last checkpoint. More precisely, because of this feature it is possible to maintain the API specification as needed.
Conclusion
To sum up everything that has been stated above, the project – Expanding the Dataspecer Tool for API Creation and Management serves the purpose of generating API specifications (in OpenAPI format) based on the data specifications designed via the tool – Dataspecer. Once the first OpenAPI specification is generated the configuration (information provided by the user) is stored which means that the user is able to go back to their latest checkpoint and continue working on the API specification. Expanding the capabilities of Dataspecer by including the feature of generating and maintaining APIs introduces several notable benefits. Firstly, it allows users to seamlessly transition from the process of data modelling to respective API specification generation within a unified platform (Dataspecer manager). This serves the purpose of streamlining the development process by eliminating the manual conversion of data schemas into API specifications. What’s more since APIs play an important role in this day and age, this feature enhances tools relevance and utility.
While the project represents a significant advancement of the Datapecer tool it is important to note that the extension may require ongoing maintenance and updates so that it remains aligned with the ever-evolving standards of the API ecosystem – in particular new versions of the OpenAPI standard.
References
[1] N. Kiesler and D. Schiffner, "What is a Good API? A Survey on the Use and," in EAI IoECon 2023 - The Second EAI International Conference on the Internet of Everything, Guimarães, Portugal, 2023.
[2] G. Jansen, "Thoughts on RESTful API design," 26 May 2024. [Online]. Available: https://restful-api-design.readthedocs.io/en/latest/resources.html.
[3] M. G. R. R. T. T. J. H. Jeremy Whitlock, "OpenAPI Specification v3.0.0," 27 May 2024. [Online]. Available: https://spec.openapis.org/oas/v3.0.0.
[4] Amazon, "What is an Event-Driven Architecture?," 27 May 2024. [Online]. Available: https://aws.amazon.com/event-driven- architecture/#:~:text=An%20event%2Ddriven%20architecture%20uses,on%20an%20e% 2Dcommerce%20website..
Appendix
Please refer to Table 1 below which describes the construct of OpenAPI as well as support provided by the developed program.
| OpenAPI Construct | Description | Support by the program |
|---|---|---|
| Metadata: openapi | Specifies the version of OpenAPI | Only supports OpenAPI version 3.0.0. The version is set by the program automatically and user is unable to change it. |
| Metadata: info | Specifies following metadata about the API – title, description and version. | Allows the user to set title, description and version of the API. |
| Servers | Specification of API server and base URL. It is possible to define multiple servers. | Allows the user to set only one base URL. Multiple servers are not supported. |
| Paths | The definitions of individual endpoints (paths) and HTTP methods that are supported by these endpoints. | Fully supports this construct. Respective path and operation constructs are created based on the user input. |
| Parameters | Operations may have parameters of following types: path parameters, query, headers or cookies. | Supports path parameter named “id” and generates query parameters for GET methods based on the properties of the data structure. Other parameter types are not supported. |
| Request Body | Specification for describing body content and media type. | Supported. Allows the user to choose which properties need to be passed in the request body. Content type is set to “application/json” and cannot be changed by the user. |
| Responses | Specification of possible status codes as well as response body schema for each operation. | Supported based on the most common HTTP status codes. |
| Input and Output Models | Definitions of common data structures utilized in the API. | Fully supported. Constructs components and schemas according to the data specifications and their data structures designed in Dataspecer. |
| Authentication | Specification of authentication methods utilized in the API. | Authentication is automatically set to “basicAuth” and cannot be changed by the user. |
Table 1 – constructs of OAS and support provided by the developed program